《Apache Spark快速入门:基本概念和例子(1)》 《Apache Spark快速入门:基本概念和例子(2)》五、弹性分布式数据集(Resilient Distributed Dataset,RDD) 弹性分布式数据集(RDD,从Spark 1.3版本开始已被DataFrame替代)是Apache Spark的核心理念。它是由数据组成的不可变分布式集合,其主要进行两个操作:transformation和action。Tr w397090770 9年前 (2015-07-13) 7672℃ 0评论8喜欢
从上周开始,我博客就经常出现了Bad Request (Invalid Hostname)错误,询问网站服务器商只得知网站的并发过高,从而被服务器商限制网站访问。可是我天天都会去看网站的流量统计,没有一点异常,怎么可能会并发过高?后来我查看了一下网站的搜索引擎抓取网站的日志,发现每分钟都有大量的页面被搜索引擎抓取!难怪网站的并 w397090770 10年前 (2014-11-14) 3211℃ 0评论6喜欢
Hive内部提供了很多操作字符串的相关函数,本文将对其中部分常用的函数进行介绍。下表为Hive内置的字符串函数,具体的用法可以参见本文的下半部分。返回类型函数名描述intascii(string str)返回str第一个字符串的数值stringbase64(binary bin)将二进制参数转换为base64字符串 w397090770 9年前 (2016-04-24) 116127℃ 90喜欢
2020年6月4日,马萨诸塞州韦克菲尔德(Wakefield, MA)—— Apache 软件基金会(ASF),超过350个开源项目和计划的全志愿者开发人员、管理人员和孵化器,正式宣布 Apache Hudi 成为顶级项目(Top-Level Project 、TLP)。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Hudi (Hadoop Upserts delete and Incrementa w397090770 5年前 (2020-06-04) 1227℃ 0评论5喜欢
Elasticsearch 6.3 于前天正式发布,其中带来了很多新特性,详情请参见:https://www.elastic.co/blog/elasticsearch-6-3-0-released。这个版本最大的亮点莫过于内置支持 SQL 模块!我在早些时间就说过 Elasticsearch 将会内置支持 SQL,参见:ElasticSearch内置也将支持SQL特性。我们可以像操作 MySQL一样使用 Elasticsearch,这样我们就可以减少 DSL 的学习成本, w397090770 7年前 (2018-06-15) 8964℃ 3评论14喜欢
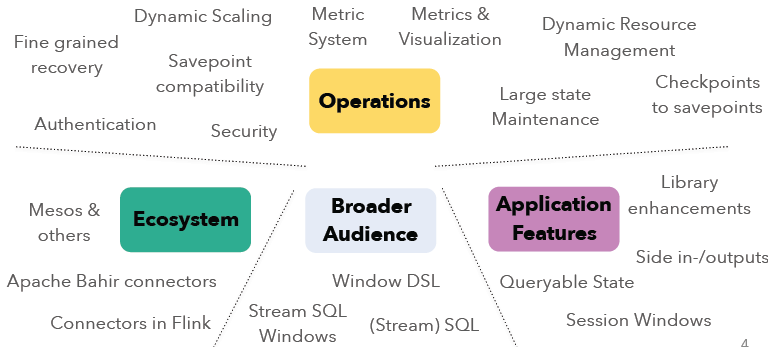
本文将概述即将发布的Apache Flink 1.2.0新功能。在Apache Flink 1.1+版本上,社区主要的集中点在操作性(Operations)、生态系统(Ecosystem)、更广泛的用户(Broader Audience)以及应用特性(Application Features)等方面的开发。各个模块的开发主要包括了如下的方向:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号 w397090770 8年前 (2016-12-18) 2855℃ 0评论4喜欢
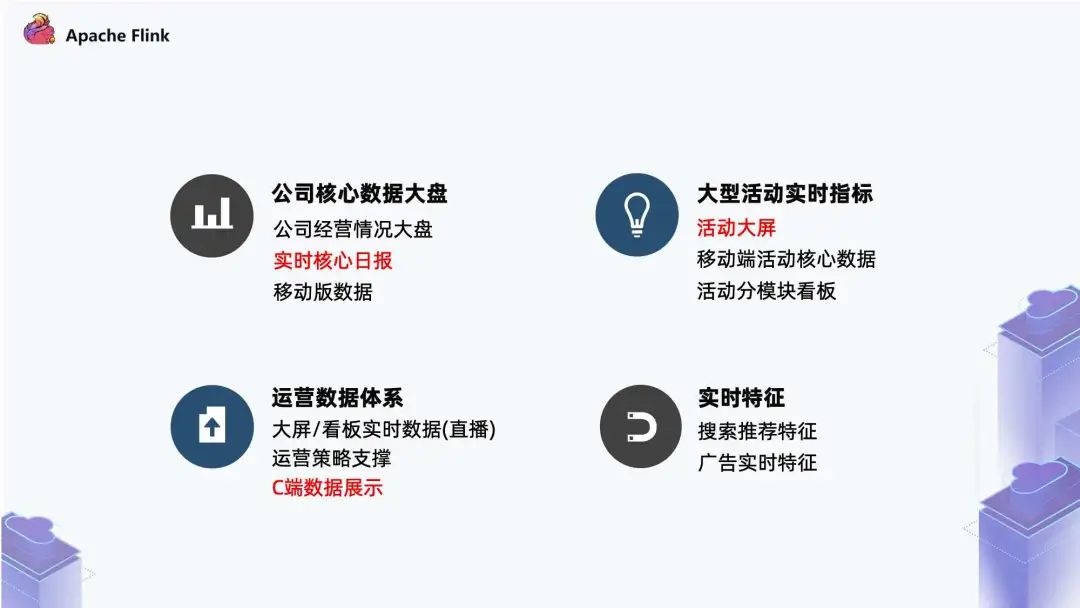
一、快手实时计算场景快手业务中的实时计算场景主要分为四块: 公司级别的核心数据:包括公司经营大盘,实时核心日报,以及移动版数据。相当于团队会有公司的大盘指标,以及各个业务线,比如视频相关、直播相关,都会有一个核心的实时看板; 大型活动实时指标:其中最核心的内容是实时大屏。例如快手的春晚 zz~~ 3年前 (2021-09-24) 786℃ 0评论5喜欢
在《Hadoop NameNode元数据相关文件目录解析》文章中提到NameNode的$dfs.namenode.name.dir/current/文件夹的几个文件:[code lang="JAVA"]current/|-- VERSION|-- edits_*|-- fsimage_0000000000008547077|-- fsimage_0000000000008547077.md5`-- seen_txid[/code] 其中存在大量的以edits开头的文件和少量的以fsimage开头的文件。那么这两种文件到底是什么,有什么用 w397090770 11年前 (2014-03-06) 20503℃ 1评论45喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 这几天比较忙,公司里面各种事,所以 w397090770 11年前 (2014-01-14) 30667℃ 4评论42喜欢
《Spark Streaming作业提交源码分析接收数据篇》、《Spark Streaming作业提交源码分析数据处理篇》 最近一段时间在使用Spark Streaming,里面遇到很多问题,只知道参照官方文档写,不理解其中的原理,于是抽了一点时间研究了一下Spark Streaming作业提交的全过程,包括从外部数据源接收数据,分块,拆分Job,提交作业全过程。 w397090770 10年前 (2015-04-28) 9201℃ 2评论9喜欢
一. 问答题1. 简单说说map端和reduce端溢写的细节2. hive的物理模型跟传统数据库有什么不同3. 描述一下hadoop机架感知4. 对于mahout,如何进行推荐、分类、聚类的代码二次开发分别实现那些接口5. 直接将时间戳作为行健,在写入单个region 时候会发生热点问题,为什么呢?二. 计算题1. 比方:如今有10个文件夹, 每个 w397090770 8年前 (2016-08-26) 3153℃ 0评论1喜欢
默认情况下,使用WordPress系统的博客登录页面都比较简单,登陆页面显示的logo是WordPress 的logo,链接也是WordPress的链接,如下图所示:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 值得高兴的是,WordPress博客系统为我们提供了很多钩子(hook)来自定义这些信息,比如Logo、链接、提 w397090770 8年前 (2016-09-03) 1911℃ 0评论6喜欢
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 但是Spark官方文档给出的属性只是简单的介绍了一下含义,许多细节并没有涉及到。本文及以后几篇文章将会对Spark官方的各个属性进行说明介绍。以下是根据Spark 1.1.0文档中的属性进行说明。Application相关属性绝大多数的属性控制应用程序的内部设置,并且默认值 w397090770 10年前 (2014-09-25) 18075℃ 1评论20喜欢
youtube-dl是一个精悍的命令程序,它可以从YouTube.com以及其他网站上下载视频。它是使用Python开发的,依赖于Python 2.6, 2.7, 或者3.2+解释器,而且这个视频下载命令是跨平台的,作者为我们带来了Windows执行文件(https://yt-dl.org/latest/youtube-dl.exe),其中就包含了Python。youtube-dl可以在Unix box,Windows或者是 Mac OS X平台上运行,支持众多视频网 w397090770 9年前 (2016-04-09) 6692℃ 0评论6喜欢
Spark Summit East 2017会议于2017年2月07日到09日在波士顿进行,本次会议有来自工业界的上百位Speaker;官方日程:https://spark-summit.org/east-2017/schedule/。 目前本站昨晚已经把里面的85(今天早上发现又上传了25个视频,晚上我补全)个视频全部从Youtube下载下来,已经上传到百度网盘(访问https://github.com/397090770/spark-summit-east-2017获 w397090770 8年前 (2017-02-15) 2799℃ 0评论15喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 11年前 (2014-01-04) 182041℃ 9评论307喜欢
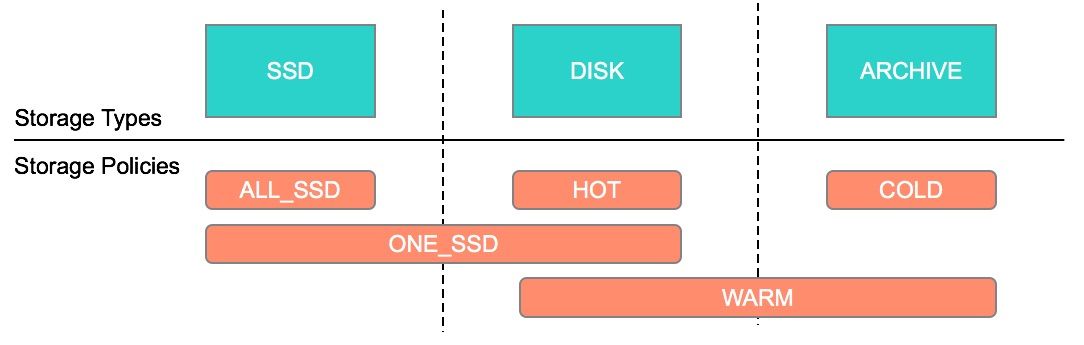
介绍HDFS 归档存储(Archival Storage)是从 Hadoop 2.6.0 开始引入的(参见 HDFS-6584)。归档存储是一种将增长的存储容量与计算容量解耦的解决方案。我们可以在集群中部署一些具有更高密度、更便宜的存储且提供更低计算能力的节点,并且可以用作集群中的冷数据存储器。根据我们的设置,可以将热数据移到冷存储介质中。通过添加更 w397090770 5年前 (2020-04-15) 1801℃ 0评论3喜欢
Spark 1.2.2和Spark 1.3.1于美国时间2015年4月17日同时发布。两个都是维护版本,并推荐所有1.3和1.2的Spark使用用户升级到相应的版本。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopspark 1.2.2(稳定版本) spark 1.2.2主要是维护版本,修复了许多Bug,是基于Spark 1.2的分支。并推荐所有使用1. w397090770 10年前 (2015-04-18) 5193℃ 0评论3喜欢
题目:有一堆石头质量分别为W1,W2,W3...WN.(W<=100000)现在需要你将石头合并为两堆,使两堆质量的差为最小。这道题目可以用01背包问题来解决。即求出和最接近sum/2的一个子集 令f(i, j)表示前i个元素中和最接近j的子集的和(有点绕),则有: f(i, j) = max( f(i-1, j), f(i-1, j-a[i])+a[i] ) ,其中a数组是用来存储所有石头的质量的。源 w397090770 12年前 (2013-03-31) 3218℃ 0评论5喜欢
本文节选自《大数据之路:阿里巴巴大数据实践》,关注 iteblog_hadoop 公众号并在这篇文章里面文末评论区留言(认真写评论,增加上榜的机会)。留言点赞数排名前5名的粉丝,各免费赠送一本《大数据之路:阿里巴巴大数据实践》,活动截止至08月11日18:00。这篇文章评论区留言才有资格参加送书活动:https://mp.weixin.qq.com/s/BR7M8Rty w397090770 7年前 (2017-08-03) 1684℃ 0评论11喜欢
如果你想配置完全分布式平台请参见本博客《Hadoop2.2.0完全分布式集群平台安装与设置》 首先,你得在电脑上面安装好jdk7,如何安装,这里就不说了,网上一大堆教程!然后安装好ssh,如何安装请参见本博客《Linux平台下安装SSH》、并设置好无密码登录(《Ubuntu和CentOS如何配置SSH使得无密码登陆》)。好了,上面的 w397090770 11年前 (2013-10-28) 9453℃ 7评论7喜欢
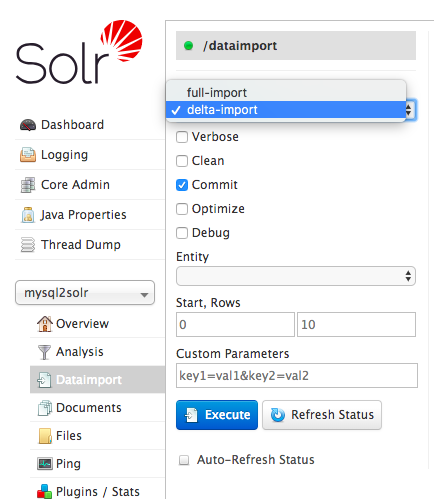
在 这篇 和 这篇 文章中我分别介绍了如何将 MySQL 的全量数据导入到 Apache Solr 中以及如何分页导入等,本篇文章将继续介绍如何将 MySQL 的增量数据导入到 Solr 中。增量导数接口为 deltaimport,对应的页面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop如果我们使用 《将 MySQL 的全量 w397090770 6年前 (2018-08-18) 1634℃ 0评论3喜欢
VSFTP是一个基于GPL发布的类Unix系统上使用的FTP服务器软件,它的全称是Very Secure FTP 从此名称可以看出来,编制者的初衷是代码的安全。本文将介绍如何在CentOS系统上安装、部署和卸载vsftp。1. 安装VSFTP[code lang="bash"][iteblog@www.iteblog.com ~]# yum -y install vsftpd[/code]2. 配置vsftpd.conf文件[code lang="bash"][iteblog@www.iteblog.com ~]# v w397090770 9年前 (2016-04-16) 2114℃ 0评论3喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-19) 7362℃ 6评论10喜欢
一、前言本文主要介绍了 Presto 的简单原理,以及 Presto 在有赞的实践之路。二、Presto 介绍Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎。起初,Facebook 使用 Hive 来进行交互式查询分析,但 Hive 是基于 MapReduce 为批处理而设计的,延时很高,满足不了用户对于交互式查询想要快速出结果的场景。为了解决 Hive w397090770 4年前 (2020-12-21) 816℃ 0评论2喜欢
本课程内容全面涵盖了Spark生态系统的概述及其编程模型,深入内核的研究,Spark on Yarn,Spark Streaming流式计算原理与实践,Spark SQL,基于Spark的机器学习,图计算,Techyon,Spark的多语言编程以及SparkR的原理和运行。面向研究Spark的学员,它是一门非常有学习指引意义的课程。 本文的视频是录制版本的,所以是画面有些不清楚。 w397090770 10年前 (2015-03-23) 43799℃ 19评论69喜欢
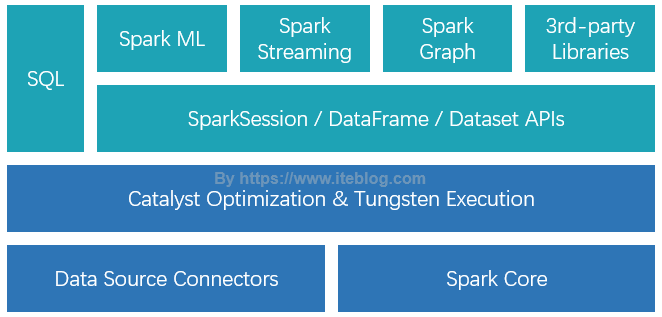
Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询和 DataFrame DSL。通过引入了 SQL 的支持,大大降低了开发人员的学习和使用成本。目前,整个 SQL 、Spark ML、Spark Graph 以及 Structured Streaming 都是运行在 Catalyst Optimization & Tungsten Execution 之上的,如下图所示:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关 w397090770 6年前 (2019-06-12) 10831℃ 0评论31喜欢
我们通过分析从2015年1月至5月下载次数最多的R包,列出了前20名流行的机器学习R包。 大多数R包都深受Kagglers大神的最爱,也被资深的笔者所赞美,而这些包的使用率或评价高低不仅仅取决于其它的包对于这个 这个包的依赖程度。还也取决于Crantastic.org并使用其众包能解决方案的用户。但是,用户评价太低以至于不 w397090770 8年前 (2016-07-17) 3875℃ 0评论5喜欢
从名字就可以看出这是笛卡儿的意思,就是对给的两个RDD进行笛卡儿计算。官方文档说明:Return the Cartesian product of this RDD and another one, that is, the RDD of all pairs of elements (a, b) where a is in `this` and b is in `other`.函数原型[code lang="scala"]def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)][/code] 该函数返回的是Pair类型的RDD,计算结果 w397090770 10年前 (2015-03-07) 11263℃ 0评论5喜欢
Spark Summit 2016 San Francisco会议于2016年6月06日至6月08日在美国San Francisco进行。本次会议有多达150位Speaker,来自业界顶级的公司。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料全部通过爬虫程序下载,如有问题 w397090770 9年前 (2016-06-15) 3374℃ 0评论9喜欢







![Hadoop入门视频分享[共44集]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/7.jpg)